ノンブロッキングI/Oプログラミング
ノンブロッキングI/Oおよび非同期処理の組み合わせでC10K問題をクリアするためには、Spring Webfluxを使うと良いらしい。 しかし、近年のマルチコアCPUに対応したスレッド処理も導入したい。
そこで、まず最初にマルチコアプログラミングについて調べてみることにする。
マルチコアプログラミング
通常の計算プログラムの動作
まず、現状のJavaのランタイム環境JVMの動作を調べてみた。 あるサイトでJavaはマルチコアで動いているという記述があったが、はたしてどうなのか調べてみた。
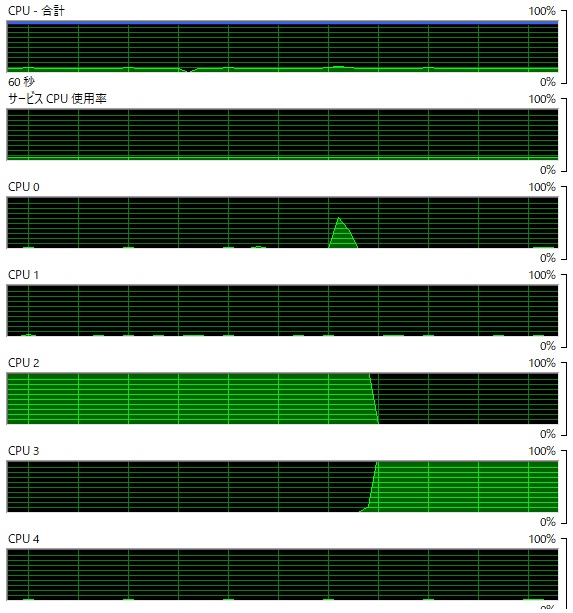
上の図1-1は、Windows10 Ryzen cpu (8コア 16スレッド)における数値計算処理時のコアの使用率を示したものである。 確かにいくつかのコアを利用しているが、同時に動いているようには見えず、ほとんどシングルコアと言ってもいい。 これでは、せっかくのマルチコアを生かしていないのは明らか。何らかのマルチコア対応をする必要がある。
考えてみれば、今回使った数値計算のマルチコア化は簡単ではなく、Javaコンパイラにお任せできるような代物ではなかった。 処理のフェーズが変わるたびにコアが変わっているのは、JVMがなんとかマルチコア化しようとしてもがいた結果のようにも見える。 結果は惨憺たるもので、シングルコアでコアが切り替わっただけに終わった。
ある数値計算処理のマルチコア処理の試み
マルチスレッドプールを作り、複数のスレッドを起動して、順次処理を割り当て、回していくことを考える。 スレッド数はいくらでもよいが、とりあえず10個程度で作ってみることにした。
マルチコア対応のjavaプログラミングは思っていたより大変であることがわかった。javaの勉強、最近サボっていたなあ・・・ 問題はキャッシュだ。コアCPUがキャッシュを参照し、実メモリを参照しないため、様々な不都合が発生するらしい。 シングルコアCPUの時代には存在しなかった問題がマルチコアで発生するため、その対策をする必要がある。
今回は、スレッド間の通信がないように、互いに独立した計算処理をマルチスレッド化することにした。 スレッド間通信がないので、キャッシュの問題は発生しない。シングルコア時代と同じ感覚でプログラム作成できる。 と思っていたが、ある程度の通信は必要のようだ。

図1-2に、全体のコントロールプログラムと計算スレッドプログラムの処理フローを示した。 各スレッドは、積分分割数に対応して台形公式で、ある与えられた積分の近似計算を行なう。 分割数が大きくなればなるほど、計算時間がかかり、計算精度も高くなる。 メインのコントロールプログラムは、小さな分割数から次第に大きな分割数へと変えながら、計算処理を各スレッドに割り振る。 各スレッドはマルチコアで動作するので、処理効率が上昇する。
当初の計画では、スレッド起動時に分割数を割り振る予定であったが、スレッドの生成と消滅を繰り返すことになり、いささか非効率。 そこで、スレッドの再利用を考え、分割数をコントロールプログラムから実行中スレッドに割り振ることにした。
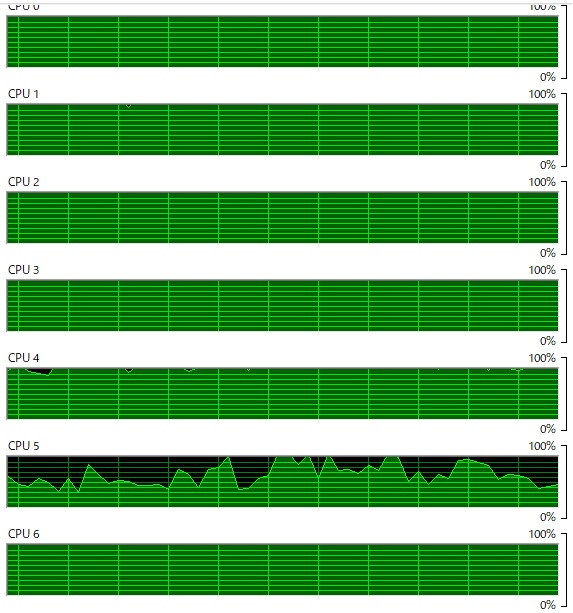
上図は、図1-2のフローを忠実に行なうプログラムを実行したときのCPU使用率を示したものである。 10個のCPUがほぼ100%の使用率であった。 原因はよくわからないが、残りの6個のCPUも数%から数十%の使用率を示していた。
特に、マルチコアで動作するように指定したわけではないが、JVMはマルチスレッドを自動的にマルチコアに割り当てるようだ。 今回使ったCPUは8コア16スレッドなのだが、OS上では16個のCPUと認識されている。 JVM上のマルチスレッドはこの16個を超えないようにする必要がある。 (超えても問題なく動作するが、スレッドの切り替えでいくらか遅くなるらしい。)
volatile修飾子
特にキャッシュ対策はしていなかったが、問題なく動作した。 volatile修飾子を付ければ、キャッシュ参照を抑制し、実メモリを参照するということだが、付けても付けなくても同じだった。 コンパイラが気を利かしてくれたようだ。 (volatileはコンパイラの最適化も抑制するとのこと。) どういうときにvolatileを付けるべきなのか、正直よくわかっていないが、スレッド間で不変でない共有メモリにはとりあえず付けることにしよう。 (定数や固定データの場合は、キャッシュだろうが実メモリだろうが関係ないので、付ける必要はない。 コンパイラの最適化も抑制する必要はないだろう。)
アトミック
共有データn[0],n[1],.,n[k],..(64ビット整数)にデータを書き込みや読み込みを行ない、スレッド間通信に使っている。 64ビットCPU、64ビットOSなので、n[k] = 1024 などの処理は機械語レベルで1オペレーションであり、分離不可能処理または最小単位の処理とも言われる。 このような分離不可能処理は、スレッドに対して処理がおかしくなることはなく、スレッドセーフである。 また、このような処理のことをアトミックであると言う。 (ただし、32ビットOSの場合の64ビット処理は1オペレーションではないので、アトミックではない。)
これに対して、m++ はアトミックではない。機械語レベルで、(Load r,addr) (Add 1) (Store r,addr)の3オペレーションになり、 分離可能処理となっている。これはスレッドセーフではない。
個々の処理がアトミックであっても、複数の処理の集まりがアトミックではないのは明らかであるから、スレッドセーフかどうかは総合的に判断する必要がある。 たまたま、今回の図2のケースでは、スレッドセーフになっている。 メインスレッドは、n[k]が0のとき値をセット。kスレッドはn[k]が0以外のとき実行し、終了すればn[k]=0にセットし待機する。 どのようなタイミングでスレッドが切り替わっても、問題が発生しないのは明らかである。
分割数でのマルチスレッド化の問題点
前節では、分割数ループで分割数を倍にしながら空きスレッドを呼び出し、実行した。 しだいに計算精度が上昇するのを確認できたが、計算量が倍々に増えていくため、計算効率は高々2倍程度であった。 10倍のCPUを使いながら2倍程度しかない効率は、少々問題である。
この方法では、最初は10個のCPUを使っているが、最後に膨大な計算量の計算が残っているにも関わらず、1個のCPUしか使わない状態になって終了する。 最後の処理が以前の処理に比べて膨大な計算となっているため、全体のスループットの半分近くを消耗するというお粗末な結果になってしまった。 この最後の処理をさらにマルチスレッド化できれば、最善であることは明らかである。 つまり、常に10個のCPUをフル稼働できるように工夫できればよい。
最深ループである超巨大な分割数の処理ループを分割し、複数のスレッドで同時処理するプログラムを作成して実行してみた。 この場合、8スレッドで実行したが、8倍の速度で処理が終了した。 つまり、8個のCPUをフル稼働で処理して、シングルコア用プログラムの1/8の処理時間で終了することができた。 さほど難しくはなかったが、小さな分割数の場合もさらに分割スレッド化するのは、あまり賢い方法とは思えない。 いくらかさらなる工夫が必要のようだ。
マルチコアの効果的運用については、この程度で終了することにする。 スレッドプールで複数のスレッドを同時実行すれば、自動的にマルチコア対応になる、ということを再確認しておく。
Ubuntuサーバでの処理結果(蛇足)
蛇足だが、Windows OSとUbuntu OSで異なる結果になるかもと思い、同じ計算処理をUbuntuサーバで実行してみた。 ほぼ、結果は同じであった。
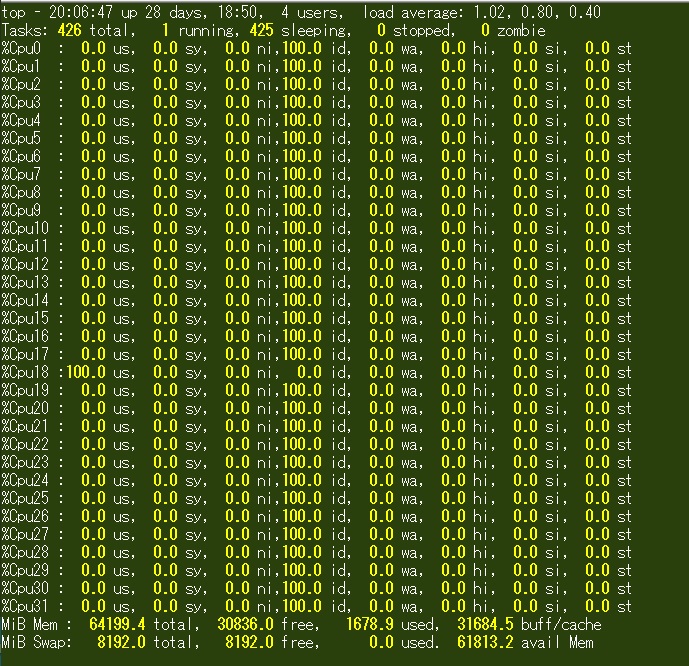
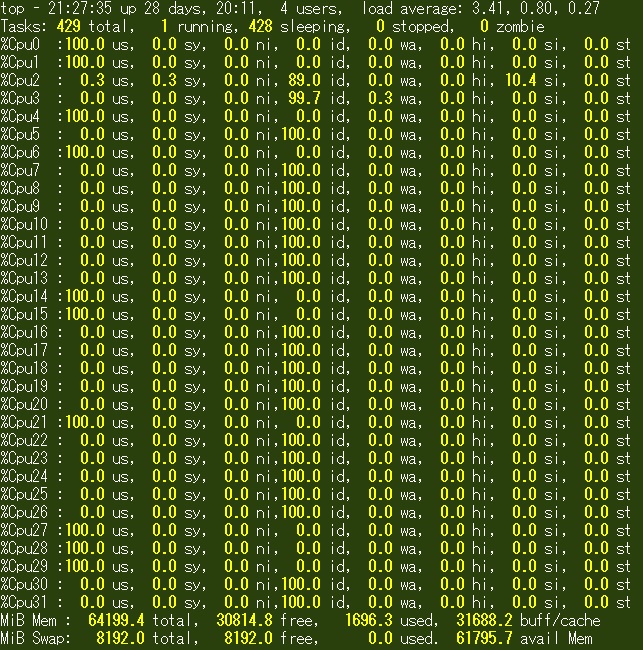
デスクトップ画面が無いので、端末でのtopコマンドによる表示となっている。 16コア32スレッドCPUなので、Windows版の2倍CPU数となっている。 一番左の段がCPU使用率であり、マルチスレッド(右)の場合、ちょうど10個のCPUが100%になっている。 他のCPUはほぼすべて0.0になっているので、Windowsとは少し違うような気もするが、同様の結果と見ていいだろう。
作成日: 更新日: